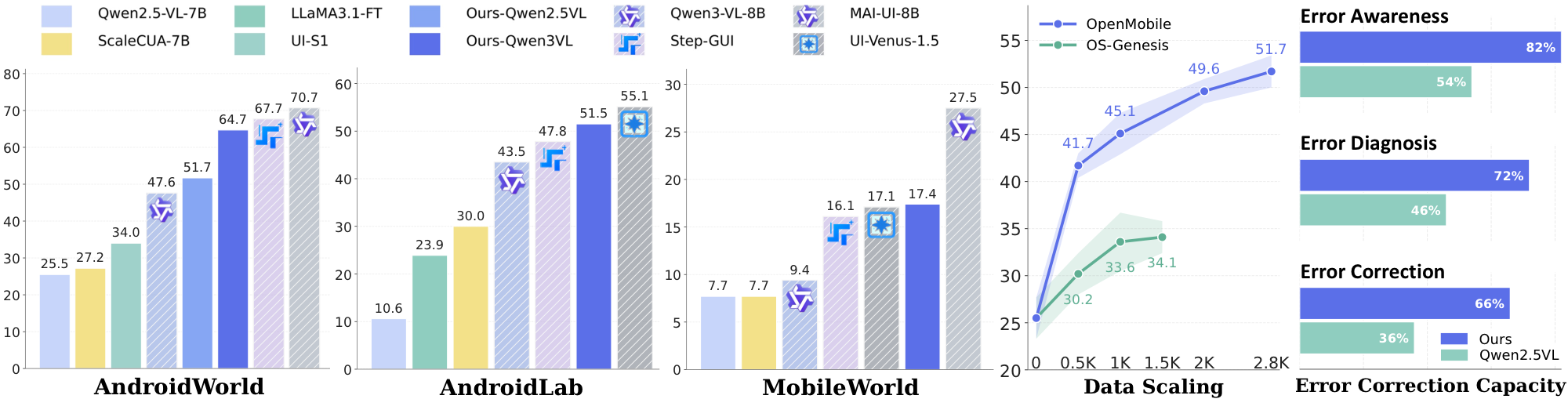
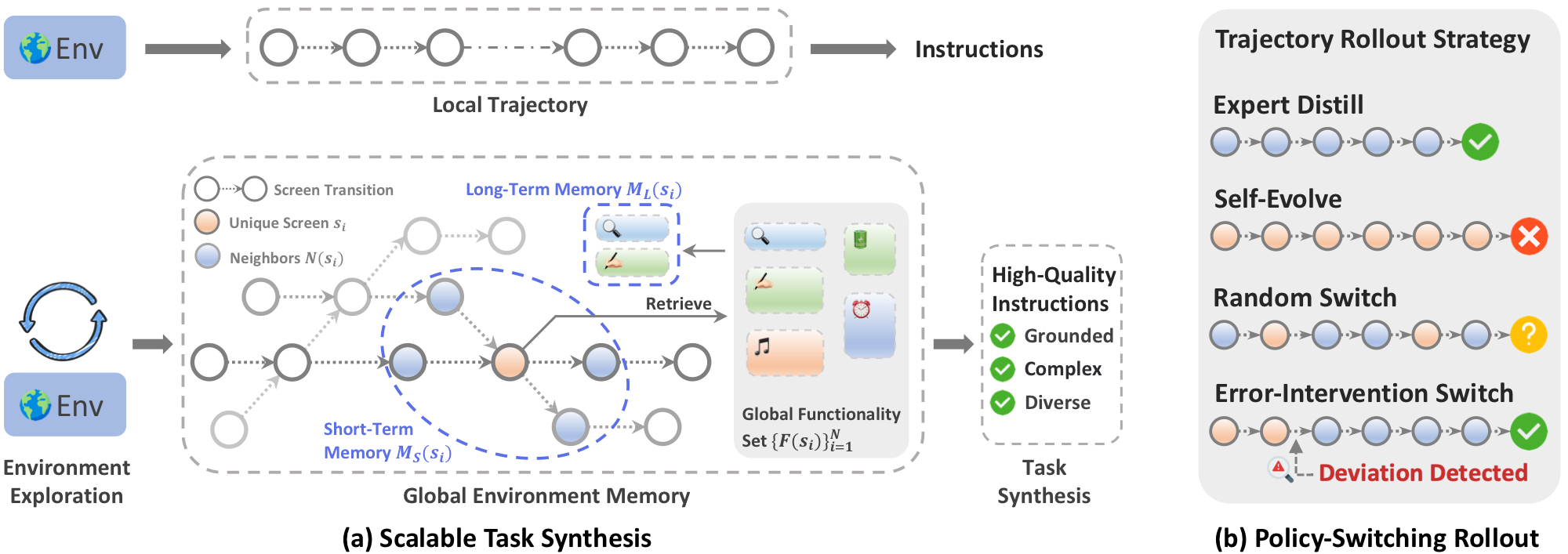
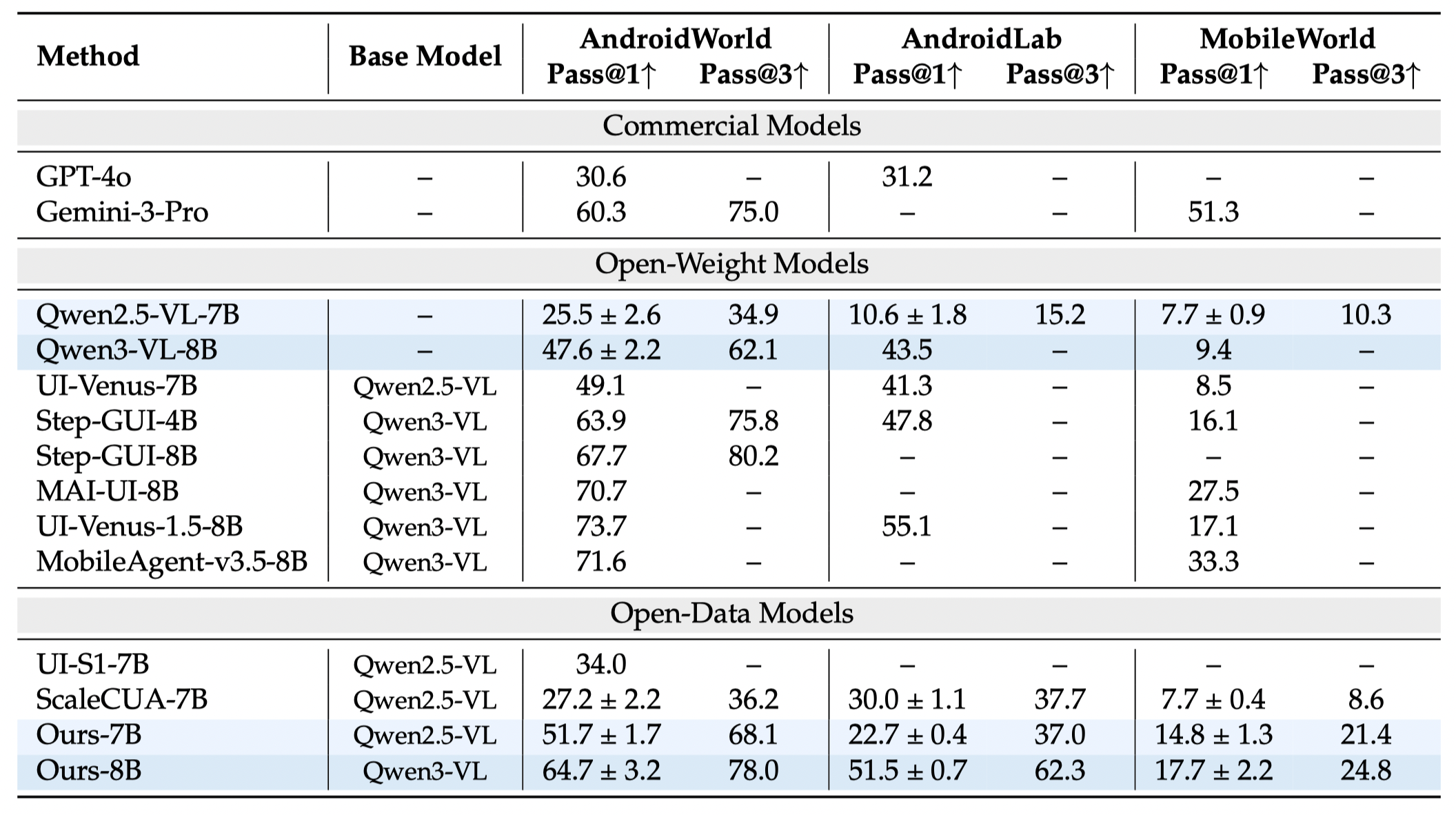
Recent industrial mobile agents approach 70% success on AndroidWorld, while open-data models remain around 30%. The open-source community cannot train models that perform competitively on dynamic mobile agent benchmarks. OpenMobile is designed to close this gap with an open recipe for task synthesis and trajectory rollout.
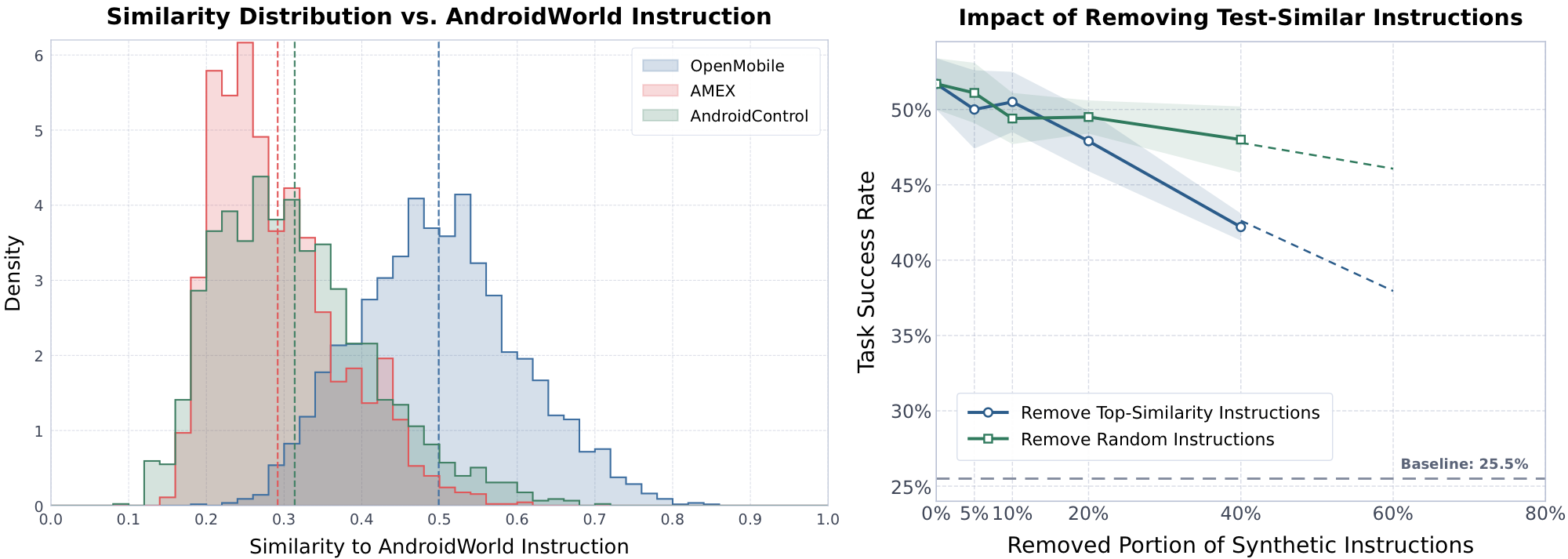
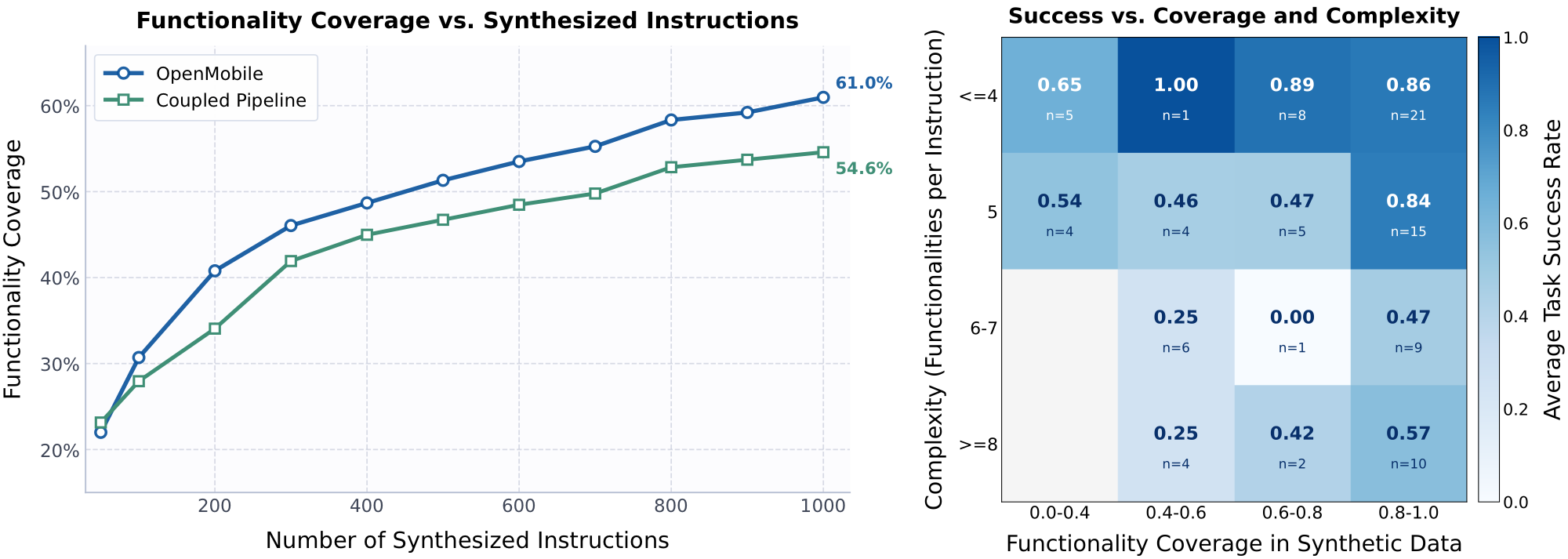
We also conduct transparent analyses on the overlap between synthesized instructions and benchmark test instructions to clarify community concerns about data leakage. The results show that OpenMobile's gains do not depend on a few test-similar instructions; instead, they are driven by broad functionality coverage and improvement in generalizable agentic capability.